Intellectual property (IP) provider Ceva Inc. announced Wednesday (Feb. 25) its latest imaging and vision processing IP core, the XM4, which is expected to start appearing in licensees' silicon before the end of 2015.
The licensable core has been optimized to address three key areas of visual processing and provides a significant performance improvement over the firm's present leading offering the MM3101, Ceva (Mountain View, Calif.) said.
The XM4 takes vision processing closer to human-like vision processing and provides a mix of scalar and vector processing units while also adding support for floating point operations, wider vector operations and enhanced memory bandwidth when compared with the MM3101. The XM4 doesn't provide direct hardware support for neural networks, but does support them running in software. More direct neural networking support is expected to follow from Ceva within two or three years (see Ceva Has Vision For Neural Network Processing).
"The XM4 architecture supports the interest in the market. At this stage we have mechanisms that support both conventional processing and neural neworks," said Yair Siegel, director of product marketing for multimedia at Ceva. "The XM4 addresses algorithms today and that we believe will come out in the near future—generic algorithms."
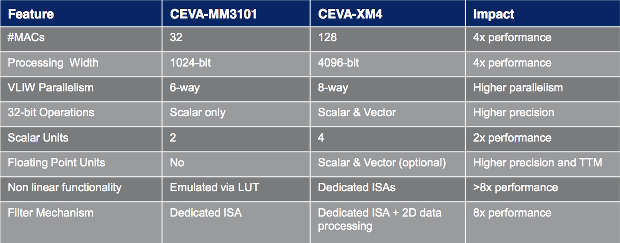
XM4 versus MM3101 architecture comparison. Source: Ceva Inc.
The XM4 addresses three sectors in the vision processing pipeline: image capture, image manipulation and visual perception. The first includes functions such as noise reduction, and depth map generation. The second are often computational photography functions such as image stabilization, low-light image enhancement, zoom, multi-frame and/or multi sensor super-resolution composition. The perception aspect includes functions such as object recognition and tracking, augmented reality and facial, gesture and emotion recognition for natural user interfaces. These are often—but not always—amenable to neural network algorithms and in current systems are so computationally intensive that they get uploaded to the cloud.
But with increasing amounts of embedded vision processing in multiple applications, there is a growing need to perform more of these functions on user equipment. The number of applications that are moving to multi-sensor image capture and that can benefit from local, energy-efficient processing is increasing rapidly. Ceva lists smartphones and tablets, automotive driver assistance systems (ADAS) and infotainment, robotics, security and surveillance, augmented reality, drones and signage as relevant applications.

XM4 versus MM3101 memory/system features comparison. Source: Ceva Inc.
The XM4's programmable wide-vector architecture and vision-oriented instruction set mean that the core achieves up to an eight-fold improvement in performance with 35 percent greater performance per watt compared to the MM3101.
The XM4 also uses a 14-stage ALU pipeline—compared with a 10-stage ALU pipeline in the MM3101—to allow use of a higher clock frequency. These would be typically up to 1.2GHz in the 28nm high-performance mobile (HPM) process from foundry Taiwan Semiconductor Manufacturing Co. Ltd. However, Siegel said that licensees are already working on implementations in less advanced silicon with 60nm critical dimensions. "As licensable IP, it can targeted at multiple processes and process nodes," Siegel said.
The IP supports real-time 3D depth map generation and point cloud processing for 3D scanning. In addition, it can analyze scene information using the most processing-intensive object detection and recognition algorithms, ranging from ORB, Haar, and LBP, all the way to deep learning algorithms that use neural network technologies such as convolutional neural networks (CNN). The architecture also supports parallel random memory access and a patented two-dimension data processing scheme. These enable 4096-bit vector processing— in a single cycle—while keeping the memory bandwidth under 512bits for optimum energy efficiency.
DSP Better Than GPU?
To help it make the point that an application-tuned DSP is better for vision processing than using a graphics processor, Ceva conducted a benchmark exercise against the Nvidia Tegra K1. Ceva claims its XM4 is 33 percent faster, 17 times smaller and consumes one-ninth the power compared to theTegra K1, which Nvidia unveiled about a year ago. Ceva said it was unable to make a comparison with the newer Tegra X1 due to lack of information, but said the company would have expected similar results.
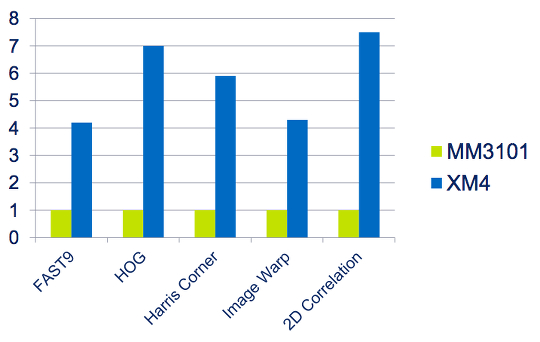
XM4 versus MM3101 comparison on computer vision algorithms. Source: Ceva Inc.
Gideon Wertheizer, CEO of Ceva, is certainly bullish about his company's latest core. "The performance per milliwatt and performance per square millimeter of CEVA-XM4 significantly exceed those of any other computer vision solution in the market, including leading GPU-based solutions," he claimed in a statement.
As befits a complex piece of processor IP, extensive effort has also been put into the software and development support for the XM4—including an Eclipse-based integrated development environment and C/C++ compiler. The core is backwards compatible with the MM3101, but includes a user extensible instruction set.
Questions or comments on this story? Contact: peter.clarke@globalspec.com
Related links:
- IHS Technology Semiconductors & Components Page
- IHS Technology MCUs and MPUs Page
- Ceva Has Vision For Neural Network Processing
- Altera FPGAs Accelerate Microsoft Neural Network Engine
- IBM Seeks Customers For Neural Network Breakthrough
- Ceva Researches Platform to Read Body Language, Emotion
- "BrainCard" Maker Project Marks Startup's Market Entry
