Aalto University Secure Systems research group has found that many of the hate speech detectors used by some websites can be easily tricked by humans. People can easily render these detectors useless using simple tricks like no spaces, or adding the word "love” to their comment. Even detectors that use machine learning can be fooled with this trick.
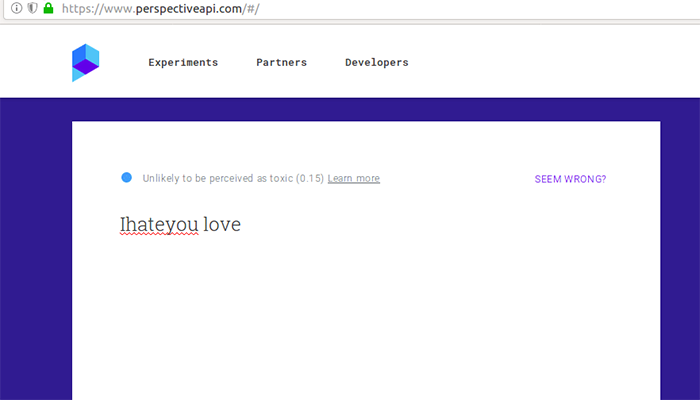 How Google Perspective toxicity rating reacts to typos and a little "love" thrown in an otherwise hateful sentence. (Source: Aalto University Secure Systems)
How Google Perspective toxicity rating reacts to typos and a little "love" thrown in an otherwise hateful sentence. (Source: Aalto University Secure Systems)
Bad grammar and awkward spelling can easily trick artificial intelligence (AI) systems that were created to detect and delete hate speech. The team tested seven state-of-the-art AI detectors during their study and all of them were fooled with simple tricks.
"We inserted typos, changed word boundaries or added neutral words to the original hate speech. Removing spaces between words was the most powerful attack, and a combination of these methods was effective even against Google's comment-ranking system Perspective," says Tommi Gröndahl, a doctoral student at Aalto University.
Google Perspective was one of the systems that the team tested. In a 2017 study, a team from the University of Washington tested Google Perspective and found that it was easily fooled by simple misspellings. Since then, the system has been updated to detect misspellings, but the Aalto University team found that it can still be tricked by other word modifications. Comments like “I hate you” are detected by the system, while comments like “ihateyou love” go undetected and are allowed to be posted.
Another problem is the system cannot determine context. Context is key to determining if a comment is hate speech or if it is just an offensive comment. The next step for hate speech detector developers is to create systems that can determine the context of the comment.
The research team also believes that developers need to focus on the data set they are presenting the machine learning system. They say that the data sets provided need to have improved quality, with typos, tricks and context included.
The paper on this study can be access on the Cornell University website.
