Powerful forces, old and new, have come together to dramatically change the way humans interact with devices. The voices of Siri, Cortana, and Echo have heralded this change to consumers and electronics developers alike, potentially marking the end of an era when tap, pinch, slide, and swipe dominate user interfaces. Very soon, the most natural form of communication—speech—will dominate human-machine interactions, and the pace of this change is taking everyone’s breath away.
“The velocity of the improvements we have made with voice is like nothing I have ever seen before,” says Kenneth Harper, senior director of mobile technical product management at Nuance Communications. “But what we have today is just the tip of the iceberg. This vision of ubiquitous speech will become a reality in the future. In the next year, we are going to see a lot of new interfaces come to market, where speech actually is the primary interface.”
The Need for Speech
The shift to voice-enabled interfaces has been accelerated by the emergence of the Internet of Things (IoT) and broad adoption of mobile and wearable devices. As the IoT takes shape, promising to provide ubiquitous connectivity to almost limitless information, consumers increasingly expect easy and convenient access to data. Unfortunately, traditional device interfaces often hinder, rather than facilitate, such access.
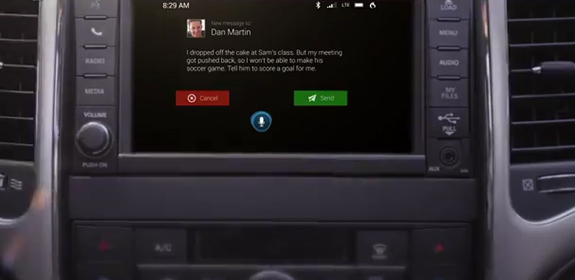 The introduction of voice interfaces has eliminated the driver-distracting nature of early automotive navigation and infotainment systems. (Courtesy of Nuance Communications.)Safety concerns preclude users of connected cars from shifting their attention from the road to interact with onboard systems via keyboards or touchpads. As a result, voice becomes the only distraction-free input medium for many automotive and infotainment systems.
The introduction of voice interfaces has eliminated the driver-distracting nature of early automotive navigation and infotainment systems. (Courtesy of Nuance Communications.)Safety concerns preclude users of connected cars from shifting their attention from the road to interact with onboard systems via keyboards or touchpads. As a result, voice becomes the only distraction-free input medium for many automotive and infotainment systems.
 Voice-based interfaces make it much easier to perform on even the most complex procedures on mobile devices. (Courtesy of Expect Labs.)Use of traditional smartphone interfaces has its own drawbacks. The devices’ small screens handicap their ability to perform all but the simplest functions well. “Most people access the Internet from their mobile devices, but only 10% of all e-commerce transactions are done on mobile devices,” says Tim Tuttle, CEO of Expect Labs. “This is because it is so tedious and cumbersome to shop for a hotel room or airline ticket. The screen is so small, and you have to navigate through a labyrinth of choices.”
Voice-based interfaces make it much easier to perform on even the most complex procedures on mobile devices. (Courtesy of Expect Labs.)Use of traditional smartphone interfaces has its own drawbacks. The devices’ small screens handicap their ability to perform all but the simplest functions well. “Most people access the Internet from their mobile devices, but only 10% of all e-commerce transactions are done on mobile devices,” says Tim Tuttle, CEO of Expect Labs. “This is because it is so tedious and cumbersome to shop for a hotel room or airline ticket. The screen is so small, and you have to navigate through a labyrinth of choices.”
These factors make voice a prime candidate for the next-generation device interfaces. Speech-recognition systems promise to provide a simpler, more efficient mechanism for handling such applications. Until recently, however, these systems lacked the intelligence required to handle complex Web searches, open-ended questions, and extensive vocabularies. The technology simply was not good enough for these kinds of applications. Speech-recognition system providers focused more on transcribing audio into words, and relied on systems that tried to match the spoken words with predefined vocabulary assembled by the developers. Unfortunately, when users spoke naturally and used words not included in the set of defined terms, the system accuracy decreased sharply.
This is, however, no longer true. The best systems today respond with almost human levels of accuracy in terms of vocabulary because the developers’ arsenal has recently been enhanced with powerful technologies.
Something Old and Something New
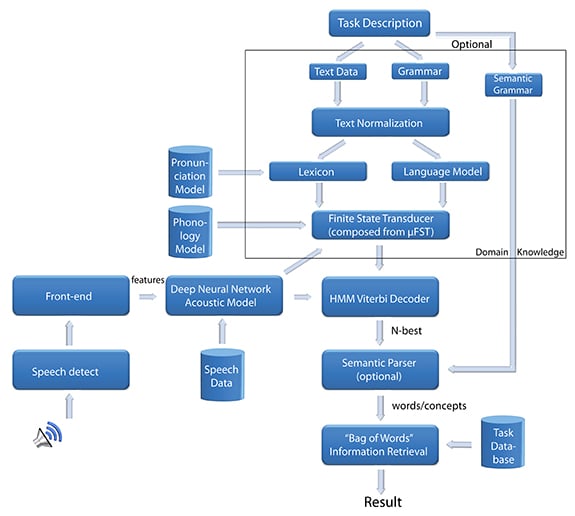
To make this leap forward, developers needed a technology that could process the complexities of language and information retrieval in much the same way that the human brain does. This translates into nonlinear, parallel processing that learns from data instead of relying on large sets of rules and programming.
For this, developers have turned to neural networks—a branch of machine learning that models high-level abstractions using large pools of data. Although neural networks (also known as deep learning) has been sidelined as a computing curiosity for several years, researchers have begun harnessing neural nets’ ability to improve speech-recognition systems.
Neural nets use algorithms to process language via deeper and deeper layers of complexity, beginning by identifying phonemes (perceptually distinct units of sound), learning the meaning of key words, and progressing to the point where they understand the importance of context. Ultimately, the algorithms put words together to form sentences and paragraphs that conform to the rules of grammar.
What makes neural nets so relevant now? Increased use of speech recognition and information retrieval systems like Siri, Cortana, and Echo has created large pools of data that train neural nets. The appearance of this data coincides with the availability of affordable computer systems capable of handling very large data sets. These two resources have enabled the developers to build bigger, more sophisticated models to create more accurate algorithms.
These new and improved models have increased the effectiveness of voice interfaces in two ways; they have improved speech-recognition systems’ ability to transcribe audio into words, and enabled a technology called natural language understanding, which interprets the meaning and intent of words.
“Natural language can take any word that a user might speak—even if it is out of bounds [not defined in a pre-established vocabulary]—and still identify some of the key words and language patterns that allow it to infer what the speaker wants or what the intent is,” says Nuance’s Harper. “So speech [recognition], which is now making use of deep neural nets to more accurately transcribe what the user is saying, is also combined with natural language understanding’s ability to look at those words and understand what some of them actually mean, doing a much better job of completing a full range of tasks that users expect these systems to perform.”
 The best voice systems today offer high levels of accuracy and task completion thanks to remarkably effective speech-recognition and natural language understanding systems. (Courtesy of Sensory.)As a result of these technological advances, voice interfaces have improved significantly in the past two years. Task completion accuracy has increased from 20% to 40%.
The best voice systems today offer high levels of accuracy and task completion thanks to remarkably effective speech-recognition and natural language understanding systems. (Courtesy of Sensory.)As a result of these technological advances, voice interfaces have improved significantly in the past two years. Task completion accuracy has increased from 20% to 40%.
Processors Built for Voice
While these software developments have greatly enhanced speech-recognition systems, hardware advances also have played a key role. Researchers credit graphics processing units (GPUs) by providing the computing power required to handle the large training data sets, which is essential in developing speech recognition and natural language understanding models. These processors possess qualities that make them ideal for voice systems.
To begin, GPUs do not burn as much power or take up as much space as CPUs, two critical considerations when it comes to mobile and wearable devices. It is their capacity for parallel computing, however, that makes GPUs so well suited for neural network and voice processing applications. These highly efficient systems provide the bandwidth and power required to convert large training data sets into the models. The graphic processors are not as powerful as CPUs, but developers can still divide larger calculations into small pieces and spread them across each GPU chip. As a result, GPUs routinely speed up common operations, such as large matrix computations, by factors from 5 to 50, out pacing CPUs.
“As we have gotten more sophisticated GPUs, we have also gotten more sophisticated ways of interacting with products through voice,” says Todd Mozer, CEO of Sensory Inc.
Cloud vs. Local…or Something in Between
Speech-recognition systems come in three flavors: cloud-based implementations, locally residing systems, and hybrids. To determine the right design for an application, issues to consider are processing/memory requirements, connectivity, latency tolerance, and privacy.
The size of a speech-recognition system’s vocabulary determines the RAM capacity requirements. The speech system functions faster if the entire vocabulary resides in the RAM. If the system has to search the hard drive for matches, it becomes sluggish. Processing speed also impacts how fast the system can search the RAM for word matches. The more sophisticated the system, the greater the processing and memory requirements, and the more likely it will be cloud-based. However, this may not be so in the future.
“All of the best intelligent system technology is cloud-based today, says Expect Labs’ Tuttle.” “In the future, that is not necessarily going to be the case. In three to five years, it’s certainly possible that a large percentage of the computation done in the cloud today could conceivably be done locally on your device on the fly. Essentially, you could have an intelligent system that could understand you, provide answers on a wide range of topics, and fit into your pocket, without any connectivity at all.”
Despite the advantages of cloud-based systems, a number of factors make speech systems residing locally on a device desirable. First and foremost, they do not require connectivity to function. If there is any chance that connectivity will be interrupted, local voice resources are preferable. In addition, local systems often offer significantly better performance because there is no network latency. This means that responses are almost instantaneous. Also, if all data remains on the device, there are no privacy concerns.
Some companies, however, adopt hybrid configurations in an attempt to cover all contingencies. By combining cloud-based and local resources, the designer gets the best of both worlds. Cloud-based resources provide high accuracy in complex applications, and local resources ensure fast responses in simpler tasks. Hybrid designs also mitigate the issue of unreliable connectivity.
Predictions of what voice systems will look like in the future indicate that there will be a place for each of these approaches. “The cloud will continue to play a big role for many years,” says Harper. “We will continue to push more advanced capability to the device, but as we do that, we will start inventing new things that we can do only in the cloud. But the cloud will always be a little bit ahead of what you can do on the device.”
Inflection Point
 Voice systems represent an amalgam of technologies that will grow in complexity, eventually understanding the meaning and intent of words and answering queries with the most applicable information available. (Courtesy of Sensory.)Rapid advances in speech-recognition and information retrieval technology put consumers and the electronics industry on notice that voice-based interfaces are about to fundamentally change the way humans interact with machines. “Within the next couple of years, speech, natural language understanding, and intelligent interfaces are going to start showing up more and more across the board in every connected device that we purchase and interact with,” says Harper.
Voice systems represent an amalgam of technologies that will grow in complexity, eventually understanding the meaning and intent of words and answering queries with the most applicable information available. (Courtesy of Sensory.)Rapid advances in speech-recognition and information retrieval technology put consumers and the electronics industry on notice that voice-based interfaces are about to fundamentally change the way humans interact with machines. “Within the next couple of years, speech, natural language understanding, and intelligent interfaces are going to start showing up more and more across the board in every connected device that we purchase and interact with,” says Harper.
As impressive as these advances are, it is important to remember that this is just the beginning. Significant obstacles still confront electronic device developers, and researchers still have huge artificial intelligence (AI) challenges to address before voice systems reach their full potential. With this in mind, it would be fair to say that this is the end of the beginning of the voice revolution.
“We will look back on this period we are in now, and the next five years, as the golden age of AI,” says Tuttle. “The numbers of advances we are seeing are remarkable, and they look like they will continue for the foreseeable future.”
