Neural networks have been around for a while but only recently has computing power become powerful enough and cheap enough to use it for image processing on a large scale. There are currently over 200 applications for neural network image processing. Processing digital images and videos to alter or enhance them is nothing new and generally not too difficult for a person to do. Having a computer automatically enhance, modify, detect or otherwise alter pictures and video without user interaction is not that easy. Image credit: Gengiskanhg / CC BY-SA 3.0
Image credit: Gengiskanhg / CC BY-SA 3.0
Imagine sifting through hours or days’ worth of security video looking for those 10 seconds of video when something interesting happens. It is a time-consuming and boring process that might even cause you to miss what you are looking for. Since video is really just a series of pictures, the same could be said for still images where you need to recognize the one shot that something is different out of thousands. Take the example of the medical world where an image shows the absence or presence of a medical condition. In this case, a highly trained individual that is capable of recognizing minute differences and looking for something specific is required to sift through many images. The movie the Andromeda Strain comes to mind as an example where fatigue caused a scientist to miss a key image that could have solved everything.
Neural networks are a way for computers to mimic the way our brain cells interact. Utilizing neural networks can enable computers to be trained to detect small changes or specific things in video or images. While this may not sound revolutionary, it is something that has been extremely difficult for a long time. If a person looks at a picture of a forest they can easily know the difference between a tree and a person or an animal and the ground. For a computer, programming what is what has been a very difficult task. One of the issues is that trees come in all shapes and sizes as do people and animals. The second issue is that the things a computer is looking for can be in any part of the picture so the computer has to figure out how to know what parts of the picture are important or not. Lastly, the computer needs to have some understanding of what a tree looks like versus a person and how to distinguish between say an arm and a branch.
Programming a computer to innately recognize an object is difficult but it turns out that training a computer is much easier. The concept of utilizing neural networks is to train a computer with as many identified examples such that it learns what a tree looks like. In the case of our forest, the computer will be trained on all different trees, lots of different people and animals, and told which is which. The neural network then builds its criteria to determine which is which and calculates the percent of a match when it sees an image.
Perhaps this process sounds simple, but one major issue is that the items in the picture may be anywhere, any size and possibly rotated or skewed in different ways. To help solve this, a process known as segmentation is used. This process separates the image into smaller more basic parts often based on things like edges and contrast. By segmenting an image into parts with high levels of contrast, it helps the computer determine which parts of the picture are more likely to contain something versus nothing. If you have a photo of a white mouse on a black background, the computer would segment the part of the picture that has the mouse to focus on and ignore the background since it is uniform and is unlikely to contain an object. The main goal of image segmentation is to make it easier for the computer to analyze an image by making what it sees more meaningful. Segmentation may also pick out other details such as the eyes of the mouse, as well as other features.
The general steps in image processing, via a neural network, are first pre-processing. In this step, noise is reduced and the image is sharpened to help the computer pick out more details. The next step is feature extraction. Feature extraction enhances images via various algorithms and edges are identified. Segmentation was previously discussed but the detected edges are clustered and the various edges and textures are segmented into groups often called super pixels. The next phase is object recognition. In this part, the image is matched to the template of trained objects. The last part is image understanding where the total scene is analyzed to gain an understanding of the picture and the objects contained.
Once a computer has been trained for various objects and has the algorithms necessary to recognize an image what good is it? Perhaps knowing how to spot a tree in a picture doesn’t help much, but spotting cancer cells might. If you want something more fun, take a look at many of the augmented reality apps on phones. Perhaps you haven’t thought about it before, but if you have ever used an app that can virtually put a hat on your head or lipstick on your lips then you have experienced the work of neural networks. These same tools can be used for facial recognition to identify criminals in a crowd or even to find Waldo.
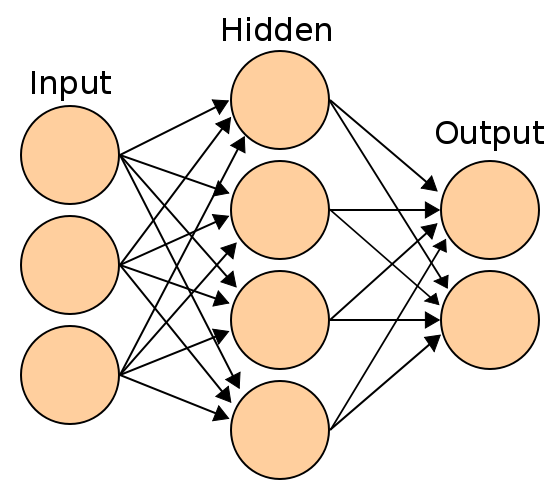 Image credit: Cburnett / CC BY-SA 3.0Once those tools are in place, you can start collecting lots of useful data, not just on a single image, but you can start checking for trends or patterns. Is a cancer spreading, shrinking or staying the same? Increasing or decreasing is the kind of information that is good to have. The interesting thing is that the computing power to do a lot of this in real time is now available in our smartphones. The training process is the slowest part and is done on higher power processors such as graphics processing units (GPU) but once the training is done, the detection algorithm can be run on a recent smartphone. You might be able to use your phone to take a picture of a skin mark and have it tell you if it is a possible match for cancer. Likewise, it could keep track of the size and shape of the blemish to determine if it is growing or changing shape. Already, apps like this exist, although at the moment their success rate is too low to be trusted, but that will improve.
Image credit: Cburnett / CC BY-SA 3.0Once those tools are in place, you can start collecting lots of useful data, not just on a single image, but you can start checking for trends or patterns. Is a cancer spreading, shrinking or staying the same? Increasing or decreasing is the kind of information that is good to have. The interesting thing is that the computing power to do a lot of this in real time is now available in our smartphones. The training process is the slowest part and is done on higher power processors such as graphics processing units (GPU) but once the training is done, the detection algorithm can be run on a recent smartphone. You might be able to use your phone to take a picture of a skin mark and have it tell you if it is a possible match for cancer. Likewise, it could keep track of the size and shape of the blemish to determine if it is growing or changing shape. Already, apps like this exist, although at the moment their success rate is too low to be trusted, but that will improve.
One of the issues when dealing with neural networks for image detection is false positives and negatives. Detection rates are based on a percent of confidence of a match and are only as good as the training data and algorithms used. In the case of medical use, it is better to have a false positive and direct a patient to seek other opinions than a false negative that may delay treatment. At the same time, no one wants to get a scare for something that is harmless.
It is clear that when it comes to processing images and video, neural networks have lots of potential to change how we see things. For better or worse, neural networks have the power to make it easier to edit, modify, enhance or just review lots of images more efficiently than a person can.