Discussions about the marvels of digital assistants like Siri and Cortana often focus on technologies like machine learning and automatic voice recognition. While these systems play an important role in bringing voice interfaces to life, limiting the discussion to these two technologies overlooks a key enabler — smart microphones.
While notoriety may have eluded these acoustic sensors, the importance of their role in providing the means for natural language interfaces to reach their full potential is unquestionable. Two factors have come together to propel far-field microphone technology onto center stage.
The first is the demand for voice-controlled devices, which require the user’s voice to be captured and processed before the device can deliver an adequate response. This entails voice extraction and speech analysis. Voice extraction focuses on detection and separation of voice input from background noise. Speech analysis, on the other hand, involves semantic processing.
The second factor is the growing trend toward connected devices and ubiquitous data access. To support this level of service, designers will have to shift from a device-centric architecture of information processing to a distributed approach. In such a system, some of the processing occurs at the device level, and the rest takes place on servers in the cloud.
All this lays the groundwork for a major transformation in user interfaces. “With the explosive growth in the Internet of Things, especially in smart homes, we’ve reached an inflection point in the way that we communicate with these embedded systems,” says Paul Neil, Vice President of Business Development at XMOS. “We’re all used to having “an app for that,” but with tens or hundreds of smart devices predicted for the home, that paradigm simply doesn’t scale, and we need to embrace a more “universal” interface — voice.”
Combining Sensing and Processing
So how do smart microphones enable voice control, and what sets them apart from conventional microphones? Unlike a traditional microphone — which simply converts acoustic pressure to voltage — a smart microphone picks up the voice input, along with ambient noise, using an array of microphones, leveraging multiple capture channels and digital signal processing  Voice-controlled devices require the user’s voice to be captured and processed before they can deliver an appropriate response. This means they need a “clean” voice input, even when operating in a noisy environment. To meet these demands, smart microphones pick up the voice input and eliminate ambient noise, echoes, and reverberations that can preclude subsequent semantic analysis. Image source: Knowles Corp. .
Voice-controlled devices require the user’s voice to be captured and processed before they can deliver an appropriate response. This means they need a “clean” voice input, even when operating in a noisy environment. To meet these demands, smart microphones pick up the voice input and eliminate ambient noise, echoes, and reverberations that can preclude subsequent semantic analysis. Image source: Knowles Corp. .
Designers can lay out arrays in a variety of topologies, ranging from a line or circle to a square or star. Generally speaking, the more microphones incorporated in the array, the better the gain and voice acquisition. To pinpoint where a sound comes from, the array must perform extensive trigonometric calculations to establish the angle of signal and the amount of signal received.
The underlying architecture of the array must also provide for low latency to ensure a natural conversational experience. It’s important to remember that design elements like large buffers can result in lags in the system’s response that adversely affect the user experience.
Each microphone in the array provides valuable information on the voice input. The general trend has been to deploy pulse density modulation output MEMS microphones because of their small size and low cost. Use of this output format, however, requires the system to convert the high-speed data stream to low-rate pulse-coded modulation (PCM) to make the signal usable in subsequent processing stages. Once the system makes the conversion to PCM, the output signals of the various microphones are processed to extract the voice input from the background noise.
Getting a Clean Signal
But how do smart microphones differentiate between the voice giving the interface a command and the background noise in the room? How can they cancel out echoes and filter out reverberations caused by walls and other hard surfaces? How can they pick up a voice from a few meters away?
To achieve these levels of performance, the system initiates a series of processes in which it detects a voice, identifies its location, and filters out acoustic elements that can degrade or preclude semantic analysis. In the first step, the system detects voice activity by applying embedded audio processing algorithms. These algorithms analyze the ambient sound using a particular threshold of sound volume within a particular frequency range.
Next, the system determines where the sound, or voice input, is coming from relative to the microphone array. This is known as the direction of arrival (DOA), which is typically described in terms of an angle, but it can also be a 2D or 3D location. Resolution and stability define the quality of DOA.
A technique called beamforming plays a key role in determining DOA. Beamforming takes signals acquired by two or more microphones and extracts the sound from a specific part of the space. This is done by creating a plane or cone-shaped segment of space that focuses on the voice input and discounts background noise 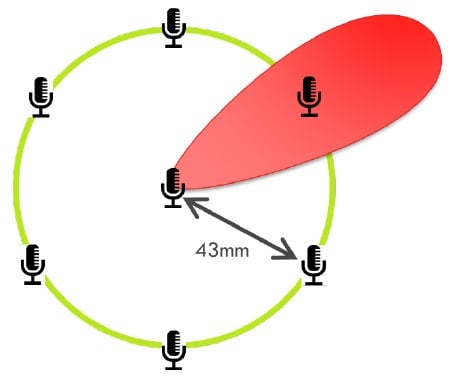 Smart microphone signal processing includes beamforming, a technique that, through the use of multiple microphones, detects the presence of an acoustic signal, estimates the direction of arrival, and eliminates background noise and reverberations. Image source: XMOS. .
Smart microphone signal processing includes beamforming, a technique that, through the use of multiple microphones, detects the presence of an acoustic signal, estimates the direction of arrival, and eliminates background noise and reverberations. Image source: XMOS. .
Smart microphones eliminate background noise in two ways. The first is through beamforming, which eliminates all sound originating outside of the area of interest. In the second, the system looks for periodically varying signals and then compensates for them within the embedded digital signal processing system, normally via spectral subtraction. Extensions of this process include echo cancellation and de-verb.
Echo cancellation is a signal processing technique that removes echoes generated by a local audio loop within the device, where a microphone picks up audio from an integrated speaker. “This process is achieved by feeding the output audio signal into the audio processor, recognizing the original audio content, and actively canceling any signal that reappears due to electrical reflections or coupling,” says Dr. Mahesh Chowdhary, Director, Strategic Platforms and IoT Excellence Center, STMicroelectronics.
Finally, signals can be corrupted by sound reflected off of walls and hard surfaces, such as a table. To eliminate these acoustic reflections, smart microphones can use additional microphones to pick up and actively cancel reflections. Another approach uses beamforming, which ignores off-axis or out-of-beam reflections.
The Brains of the Operations
All these functions rely on embedded digital signal processing to run the algorithms tailored to perform the tasks. The processors typically fulfill microphone aggregation, microphone and voice DSP functions, and control functions 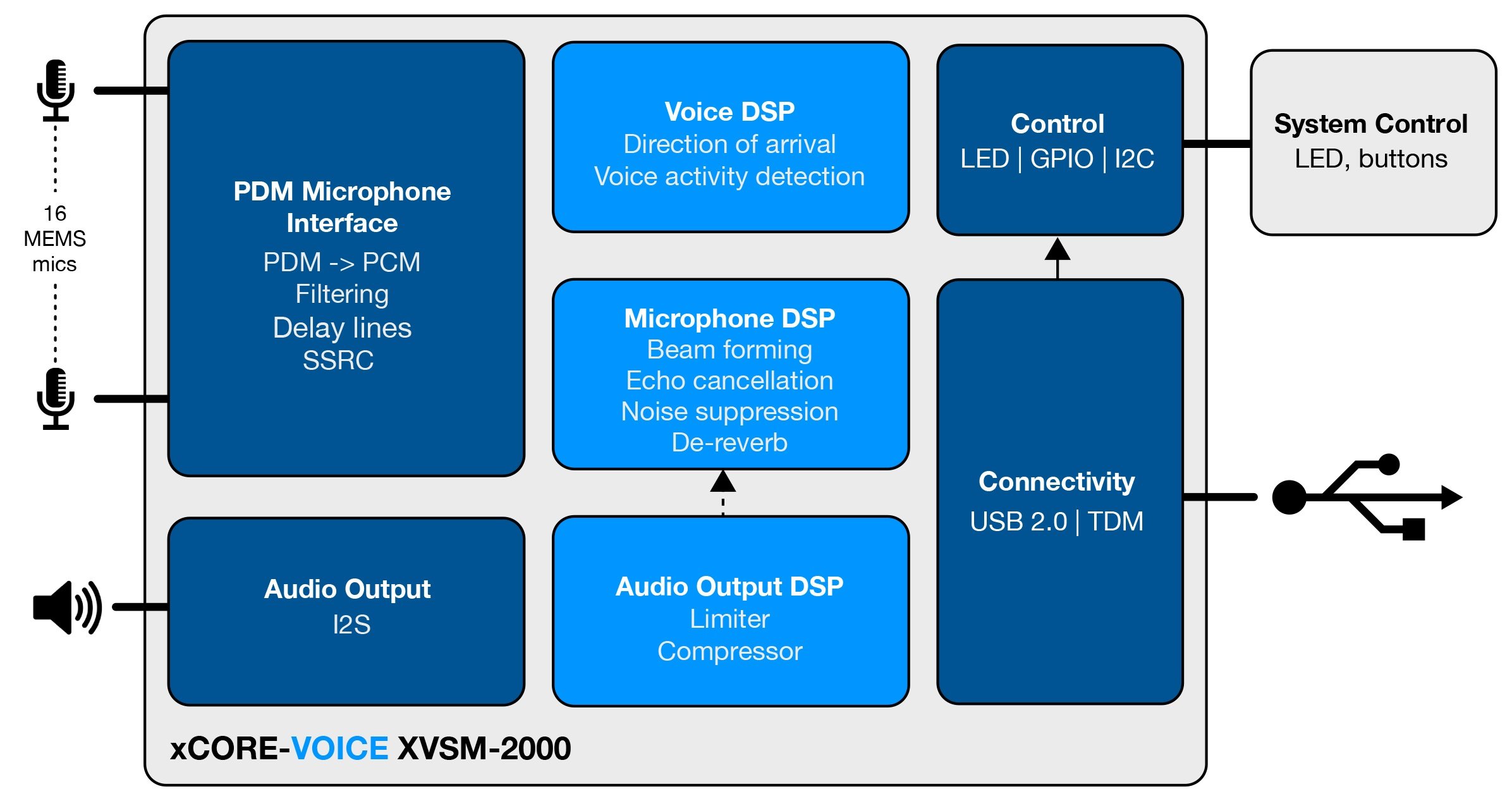 Smart microphone processors convert pulse density modulation output from MEMS microphones into pulse-coded modulation format, making the signal usable in subsequent processing stages. Once this conversion has been completed, the output signals of the various microphones are processed to extract the voice input from the background noise. This involves functions like voice activity detection, direction of arrival, beamforming, echo cancellation, and noise suppression. Image source: XMOS. .
Smart microphone processors convert pulse density modulation output from MEMS microphones into pulse-coded modulation format, making the signal usable in subsequent processing stages. Once this conversion has been completed, the output signals of the various microphones are processed to extract the voice input from the background noise. This involves functions like voice activity detection, direction of arrival, beamforming, echo cancellation, and noise suppression. Image source: XMOS. .
“Microphone aggregation sees multiple microphone inputs combined together into a single stream,” says Neil. “These streams can be processed to create a highly directional microphone using direction-of-arrival and beamforming DSP algorithms, while echo cancellation, noise suppression, gain control, and a range of other audio DSP capabilities are used to effectively separate out the target speaker. The captured, processed voice samples are then securely transferred to the automatic voice recognition system.
A Question of Power
Performing this level of processing, as well as providing always-on services , comes at a cost in terms of energy consumption. And energy efficiency poses one of the greatest hurdles that the designers of smart microphones must overcome.
To stay within power budgets, smart microphones use dynamic operating modes to optimize power consumption during system sleep and wake cycles. In many systems, this multi-mode feature allows most of the system to stay in a low-power sleep mode. While the system is sleeping, the microphone actively listens for speech. If speech is detected, the rest of the system is sequentially turned on to perform signal processing, keyword detection, and request response. This staged power approach minimizes battery drain in an always-on system.
“To achieve low power consumption, the key challenge for the smart microphone is to accurately determine speech versus background noise, waking the system only when necessarily,” says Mike Adell, Vice President , Intelligent Audio, Knowles Corp. “Think about when you are in a coffee shop with a lot of background noise, you don’t want your device to be awake all the time and drain your battery when you’re not talking to it.”
Looking Forward
Any attempt to paint a picture of the future of smart microphones has to recognize tha Consumers expect personal assistants and hands-free voice interfaces to support always-on capabilities. To accomplish this, smart microphone developers must use design techniques that mitigate power consumption. Meeting the conflicting demands of availability and power efficiency poses one of the greatest challenges to smart microphone providers. Image source: Knowles Corp. t the developers of the technology are just getting started. “Improved software algorithms and hardware will lead to higher performance compared to current-generation smart microphones,” says Chowdhary.
Consumers expect personal assistants and hands-free voice interfaces to support always-on capabilities. To accomplish this, smart microphone developers must use design techniques that mitigate power consumption. Meeting the conflicting demands of availability and power efficiency poses one of the greatest challenges to smart microphone providers. Image source: Knowles Corp. t the developers of the technology are just getting started. “Improved software algorithms and hardware will lead to higher performance compared to current-generation smart microphones,” says Chowdhary.
As mobile and wearable devices increasingly incorporate smart microphones and consumers consistently expect always-on performance, developers will focus their efforts even further on reining in power consumption. As a result, you can expect a drive toward ultra-low-power controllers.
But perhaps the most important development will take place in smart microphone programmability. Incorporating more programmability into the platform will likely create opportunities to improve control and signal processing algorithms, which in turn will allow different beamforming and DOA algorithms to be implemented by temporal alignment analysis of the input signals.
While developers will move forward in these technological areas, you can expect the tug of war between local and remote processing models to continue. As a result, developers will have to provide additional performance to the voice controller to support greater levels of local automatic speech recognition, which in turn will affect connectivity requirements.
The bottom line? Smart microphones will increasingly become a standard component in the growing list of devices populating the Internet of Things, and the ability to control smart home systems via voice-based interfaces will become the norm. As a result, the concept of the interface will change, perhaps ushering in an era of “no-interface” devices.