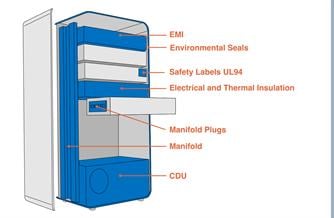
Researchers from Carnegie Mellon University (CMU) created a new method to improve the detection accuracy of self-driving cars, enabling them to recognize even what it cannot see, like empty space.
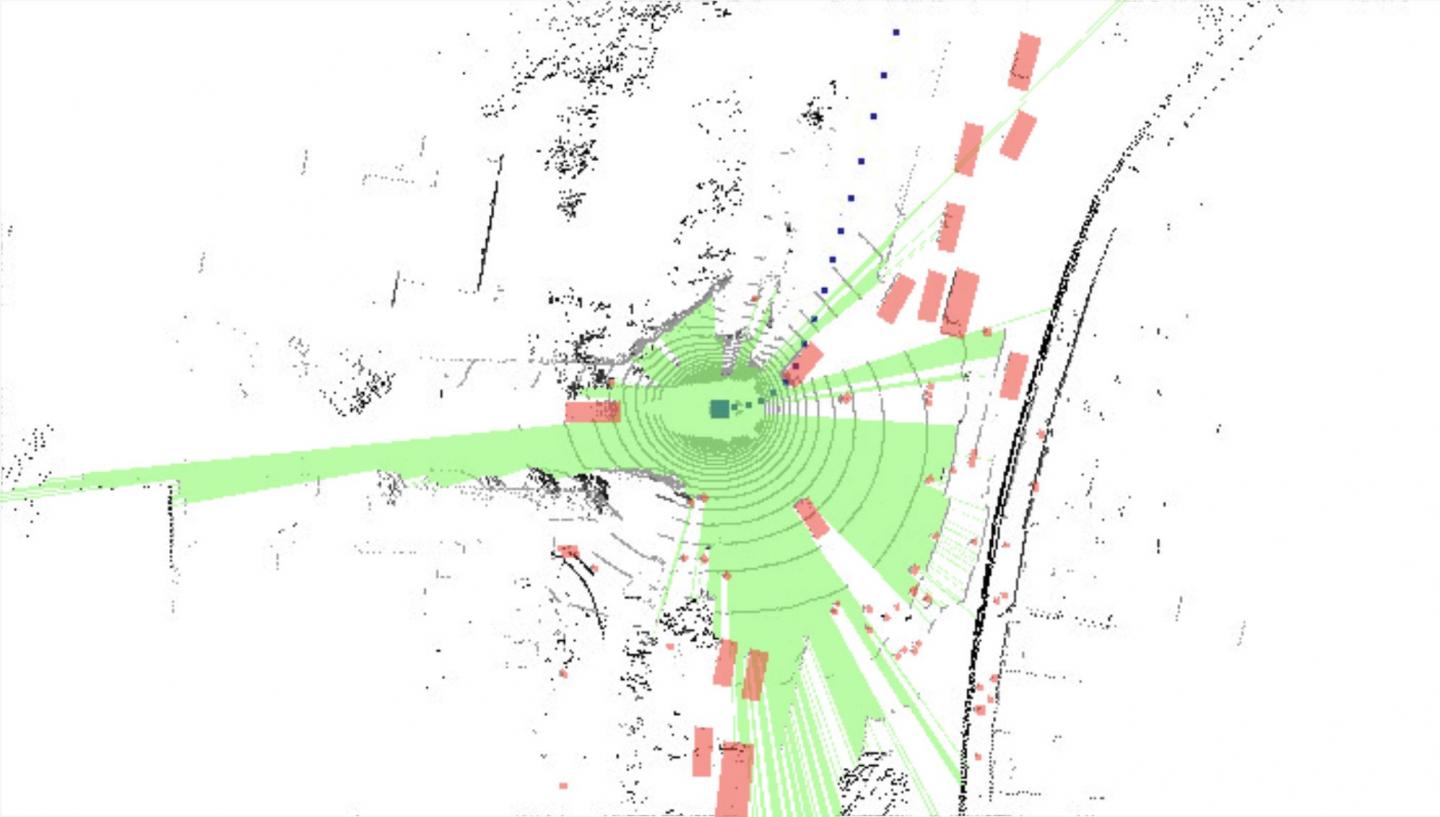 New CMU research shows that what a self-driving car doesn't see (in gre en) is as important to navigation as what it actually sees (in red).Source: Carnegie Mellon University
New CMU research shows that what a self-driving car doesn't see (in gre en) is as important to navigation as what it actually sees (in red).Source: Carnegie Mellon University
Humans know that objects in their sight may obscure the view of things ahead of their path, but self-driving cars cannot reason about the objects around them. Self-driving cars use 3D data from lidar to represent objects as point clouds. The system then tries to match point clouds to its library of 3D representations of objects. This is a problem because 3D data from car lidar is not really 3D. Sensors cannot see blocked parts of an object and current algorithms do not reason blocked areas.
The new work allows self-driving car perception systems to consider visibility by enabling the systems to reason about everything the sensors are seeing. Reasoning visibility is used by companies when building digital maps. Map building fundamentally reasons what areas in an image are empty spaces and what areas are occupied. This does not typically occur in live processing of obstacles at traffic speeds. To develop the new system, the team borrowed techniques from map-making to help the self-driving car system reason about visibility when recognizing objects.
The team tested their system against the standard benchmark. The team’s new method outperformed the current top-performing technique. Detection improved by 10.7% for cars, 5.3% for pedestrians, 7.4% for trucks, 18.4% for buses and 16.7% for trailers.
Researchers say that the previous system's failure may be due to the fact that these systems did not take into account the computation time. The new method takes only 24 milliseconds to run.
This research was virtually presented at the Computer Visions Pattern Recognition (CVPR) Convention.