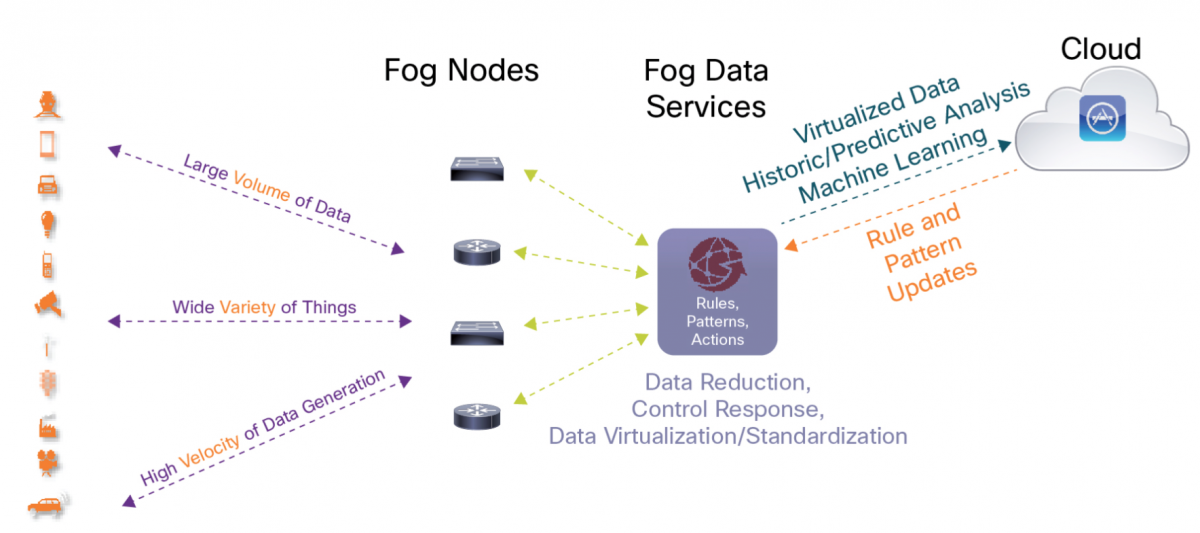
Fog computing promises to move data to the best place for processing by aggregating compute, memory and software resources in fog nodes and gateways. This approach promises to eliminate shortcomings that prevent the IoT from reaching its full potential. Image source: Cisco SystemSomething about the Internet of Things (IoT) is not quite right. The dynamics between data sources, such as sensors and the cloud, fall short in critical applications. The result: big data may just as well be no data.
Fog computing promises to move data to the best place for processing by aggregating compute, memory and software resources in fog nodes and gateways. This approach promises to eliminate shortcomings that prevent the IoT from reaching its full potential. Image source: Cisco SystemSomething about the Internet of Things (IoT) is not quite right. The dynamics between data sources, such as sensors and the cloud, fall short in critical applications. The result: big data may just as well be no data.
Seeing the discrepancy between concept and reality, many technology visionaries and systems providers now advocate a topology called “fog computing” that creates a layer between the two poles of the network. This layer will aggregate compute, storage, control and network resources closer to the sources of data.
Proponents of fog computing do not see this distributed approach replacing the cloud, but complementing it instead. Fog computing promises to move data to the best place for processing and, in doing so, mitigate or eliminate shortcomings that prevent the IoT from delivering the benefits its creators have promised.
Shortcomings
To better understand why industry leaders are pushing for the implementation of fog computing, it is helpful to look at the areas where cloud computing falls short. To do this, you have to look at the expectations it has to meet. Reliance of the IoT on the cloud-based model of processing, analyzing and storing data has proven inadequate for applications that require low latency and high reliability. In addition, the increase in the volume and velocity of data streams routed to the cloud presses network bandwidth beyond its limits, demanding a new approach to data processing and analysis. Image source: Cisco Systems
Reliance of the IoT on the cloud-based model of processing, analyzing and storing data has proven inadequate for applications that require low latency and high reliability. In addition, the increase in the volume and velocity of data streams routed to the cloud presses network bandwidth beyond its limits, demanding a new approach to data processing and analysis. Image source: Cisco Systems
Early visionaries saw the IoT sweeping aside the realm of the traditional desktop and embedding information and communications systems into almost all physical objects. Network experts expected these objects to generate mountains of data that would be stored, processed and analyzed in the cloud, ultimately providing the insight sought by adopters. In reality, this paradigm simply does not work in all scenarios. This is particularly true of industrial and healthcare applications.
For example, many manufacturing, utility and transportation applications require reliable and immediate processing and analysis of operational data. Time-sensitive, mission-critical processes and applications cannot afford to wait for sensor and control data to make the roundtrip between the data source and cloud-based platforms. By the time data essential to these applications reaches its destination, a system failure may have shut down important segments of operations.
Some healthcare applications also require the same stringent latency performance. But these applications also demand that the privacy of patient data is guaranteed, which makes off-site storage problematic.
 Fog computing promises to meet the needs of healthcare facilities, which often require low latency and strict privacy of patients’ medical data. Image source: FogHorn SystemsAnother problem area is network capacity. The cloud-based approach presses network bandwidth beyond its limits. Industry experts predict that an estimated 50 billion objects will be connected to the internet by 2020, generating more than two exabytes of data per day. Moving this volume and variety of data to and from the cloud will require bandwidth that simply is not available. The fact is that prevailing cloud models simply cannot handle the volume, variety and velocity of data that the IoT will generate.
Fog computing promises to meet the needs of healthcare facilities, which often require low latency and strict privacy of patients’ medical data. Image source: FogHorn SystemsAnother problem area is network capacity. The cloud-based approach presses network bandwidth beyond its limits. Industry experts predict that an estimated 50 billion objects will be connected to the internet by 2020, generating more than two exabytes of data per day. Moving this volume and variety of data to and from the cloud will require bandwidth that simply is not available. The fact is that prevailing cloud models simply cannot handle the volume, variety and velocity of data that the IoT will generate.
“The promise and prevalence of cloud computing platforms necessitated that conventional sensors and normally isolated devices be connected [to the Internet] so that the efficiency, productivity and cost savings of those promises could be realized,” says Todd Edmunds, global manufacturing solutions architect of the IoT at Cisco Systems. “With so many diverse types of devices, there needed to be a way to connect to them and to extract, aggregate and transfer the data before sending it up to a bandwidth-constrained and frequently unavailable cloud infrastructure.”
Moving to the Edge of the Network
Fog computing remedies these flaws by moving compute, analytics and data-storage resources in the form of fog nodes closer to the source of data, at the edge of the network. A fog node consists of a software stack that enables pre-processing, as well as advanced analytics. These devices can process and analyze multiple data streams from sensors and other sources to identify patterns, detect conditions and derive insights. They also provide local storage and caching for big data analytics in the cloud.
 A fog node consists of a software stack that enables pre-processing, as well as advanced analytics. These devices can collect, process and analyze multiple data streams from edge data sources to identify patterns, detect conditions and derive insights. Fog nodes also coordinate the flow of data from the network’s edge to the cloud. Image source: Cisco Systems“Fog computing overcomes the fact that traditional edge devices and machines often have fixed functions and cannot easily be enhanced with new capabilities as technology and know-how advances,” says Stan Schneider, CEO of RTI.
A fog node consists of a software stack that enables pre-processing, as well as advanced analytics. These devices can collect, process and analyze multiple data streams from edge data sources to identify patterns, detect conditions and derive insights. Fog nodes also coordinate the flow of data from the network’s edge to the cloud. Image source: Cisco Systems“Fog computing overcomes the fact that traditional edge devices and machines often have fixed functions and cannot easily be enhanced with new capabilities as technology and know-how advances,” says Stan Schneider, CEO of RTI.
As far as their place in the network topology, fog nodes can be deployed wherever there is a network connection. The key to fog computing is that the links between the sensors and fog nodes have higher bandwidth, lower latency and greater reliability than wide-area connections to cloud services or centralized data centers.
Upstream, you find “edge gateways.” These devices typically aggregate data from fog nodes and orchestrate data flow among fog nodes, depending on the network’s topology. An edge gateway can have significant compute, memory and network resources, either serving data directly to applications within a facility or communicating with cloud resources.
“A robust, multi-tiered Industrial Internet of Things [IIoT] system operates much like a well-run organization,” says Tom Luczak, co-founder and CTO of Flow Corporation. “One can think of the fog nodes as the bulk of the workforce in that they have domain expertise in their immediate roles and can operate semi-autonomously, but still report to a higher-level manager, like an edge gateway. These edge gateways coordinate the actions of the far edge and ensure that operations among the fog nodes are flowing smoothly.”
Building Materials
As with any other transition to a new system, one of the first questions to be answered is the following: Are all of the necessary components available to build the new infrastructure? In the case of fog computing, the answer is yes…and no.
From a technology perspective, many of the individual components exist. Fog-computing applications are already being deployed in hospitals, the smart grid and autonomous cars. That said, specific-purpose compute devices are being introduced almost daily. These devices must meet the needs of the particular market they serve, such as harsh-environment switching for manufacturing. Some early entrants to the fog computing market have developed gateways that include miniaturized analytics engines that can run on low-footprint machines, such as this FogHorn edge gateway. The goal is to provide edge applications with access to sensor and machine data, as well as send aggregated data to the cloud for further analysis and processing. Image source: FogHorn Systems
Some early entrants to the fog computing market have developed gateways that include miniaturized analytics engines that can run on low-footprint machines, such as this FogHorn edge gateway. The goal is to provide edge applications with access to sensor and machine data, as well as send aggregated data to the cloud for further analysis and processing. Image source: FogHorn Systems
More, however, still has to be done. “The groundbreaking work is being done in the architecture of these systems—defining how the data flows, where the services live and building a repeatable template that can be applied across industries,” says Luczak.
But what about the sensors that already populate the grid, factory floors and healthcare facilities? Industry leaders disagree on the effect fog computing will have on the design, composition and functions of smart sensors.
Some see the new computing paradigm enhancing smart sensor capabilities. “Fog computing infrastructure can impact the development of smart sensors in a very positive way,” says Sastry Malladi, CTO at FogHorn Systems. “Thanks to the significant data processing and analytic capabilities at the edge, smart sensor vendors can focus on capturing a wider variety of data and increasing frequency without worrying about the limitation of network availability, bandwidth, and latency for downstream processing and analytics.
Smart sensors may even evolve into another form. “Specific types of sensors will continue to be developed that will include the smarts necessary to become edge or fog nodes by themselves,” says Edmunds.
Others see fog computing "dumbing down" smart sensors. “Fog computing can minimize the smarts required by smart sensors, reducing sensor cost,” says Schneider. “Sensor data can be more efficiently processed in upstream, general-purpose fog nodes.”
The disparity of views provides a good reminder that fog computing is very much in the early stages of its development, and nothing is set in stone.
Software for Fog Computing
Cisco Systems coined the phrase “fog computing,” and as you might expect, it is one of the first companies to develop software for the fog layer. Its IOx middleware aims to enable fog nodes to host applications. Cisco—along with other nascent fog-technology providers like FogHorn Systems and RTI—contend that this software must have small footprints to run on the various devices at the edge.
In addition to the general view regarding the size of fog software, Cisco also believes that three other elements will play key roles in the software’s development. First, microservices architectures will become a building block used to create distributed software systems that can share information and data effectively. This approach to application development advocates building large applications using a suite of modular services. Each of these modules supports a specific function and uses a well-defined interface to communicate with other modules.
Second, another key fog software development tool will be container environments, such as LXC. These make it simpler to run an application on multiple fog nodes.
Finally, software developers will do well to rely on open-source applications, protocols (for example, UPC-UA) and message bus technologies like DSA. These will facilitate the transmission of information to fog nodes, as well as to cloud applications.
The ultimate goal is to create powerful yet flexible edge analytics applications. “Edge analytics software needs to be a general-purpose, high-performance and scalable platform, where analytics applications can be developed to address specific IIoT needs,” says Malladi. “It also needs to be flexible in resource consumption. More specifically, systems should be able to leverage the new generation of powerful gateway machines.”
Early Returns
Fog computing is just getting started. Even so, it is pretty clear that its importance to the IoT’s continued growth almost guarantees that significant resources will be committed to fleshing out this technology. To predict what the mature technology will look like is impossible. Not only are fog nodes and software just beginning to evolve, but their ultimate form and function is being defined by constantly changing compute, memory and communications technologies.
The shift to a more distributed approach is but one of the changes in course likely to occur as the IoT evolves. It is a good bet that more changes will follow.